yolov5简要介绍
什么是yolo
yolo(you only look once)是一种one-stage类别的目标算法,可以直接回归于物体的位置坐标和类别概率,速度相比two-stage要快。因为直接通过主干网络给出类别和位置信息,没有使用RPN网路,所以准确度要低。比较经典的one-stage检测算法包括YOLO,SSD等。
yolo于16年被提出,这是发表在计算机视觉顶会上国内镜像原文网址,有兴趣的可以看一下:
http://xxx.itp.ac.cn/pdf/1506.02640v5
当然有one-stage自然也有two-stage类别的目标算法。
two-stage的算法是先通过对物体框定候选框,再对每个候选框进行分类、修正位置。这种算法速度较慢,因为它需要多次运行检测和进行分类。
yolov5简单操作
接下来是讲解如何用yolov5跑通自己的模型!
首先你需要确保你能访问谷歌,并且你还要有一个Google邮箱账号。因为本教程是基于谷歌的colab来进行的。
colab
这里介绍一下colab。colab是Google提供的一个在线工作平台,colab的py代码的运行是基于jupyter的,在学CV的教程中有很多教程是在jupyter上进行的,能够分块执行代码,并能添加注释(你们刚刚开始学CV时看到许多教程应该有这种体会)。
当你在运行程序时colab会创建一个虚拟机,也就是连接你的代码时colab需要分配实例空间,在这上面运行代码并在运行结束后回传至你的电脑。在接触深度学习后,你会知道GPU运行速度会远超CPU,没有一个好的显卡、算力不足等情况在跑模型时会很痛苦。所以使用colab的好处是可以白嫖Google的算力!!
第一步
首先将预识别物体进行拍照,提高识别物体的准确率,建议大家多个角度拍摄。整个照片集最好有40张以上
在桌面上新建一个如下规格的文件夹。

将拍摄好的照片按一定数量放入images/train和images/val中。
注意:两个文件夹的照片数量一定为2的倍数!
第二步
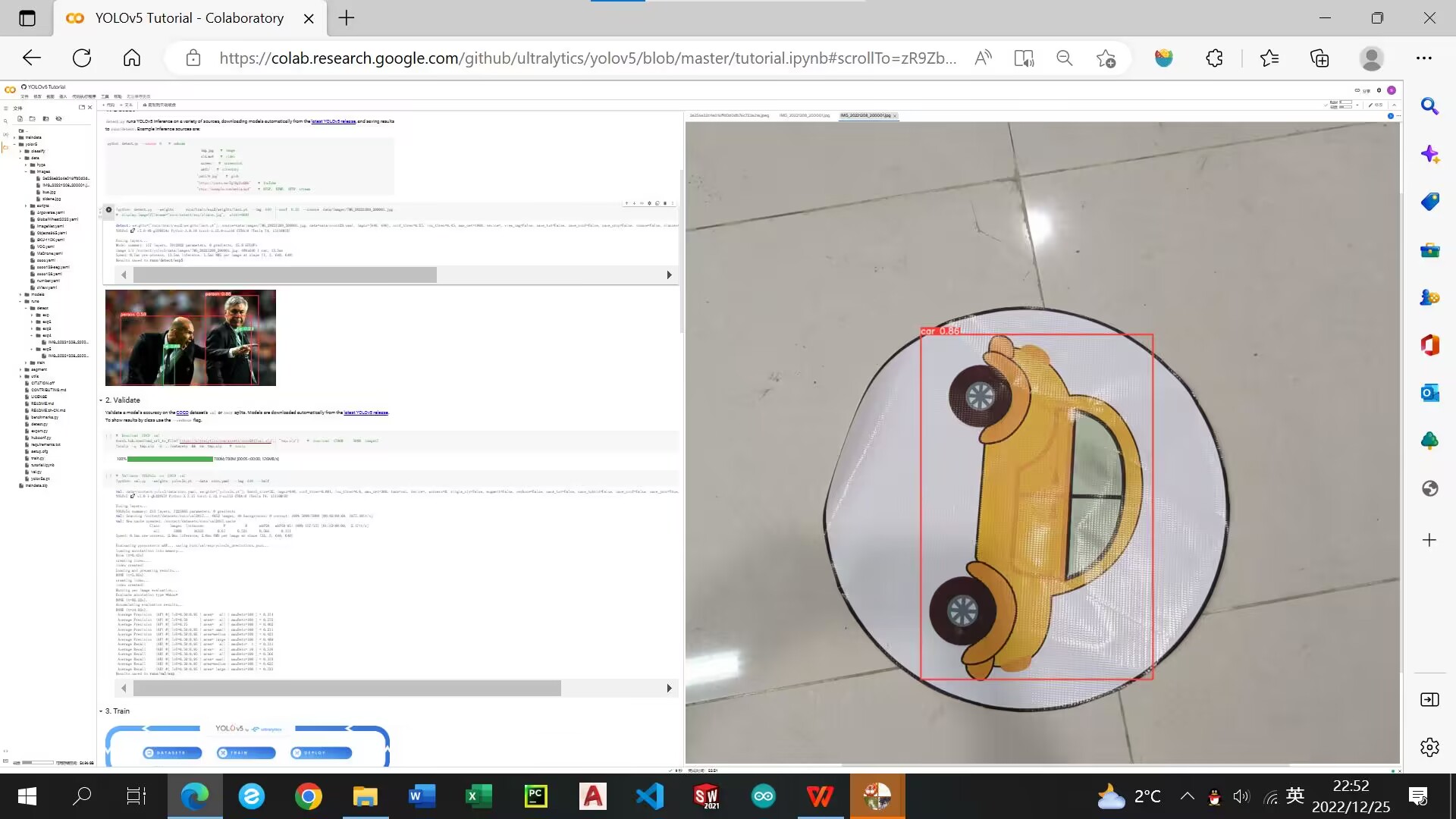
按图片点进这个 网址
点击get started
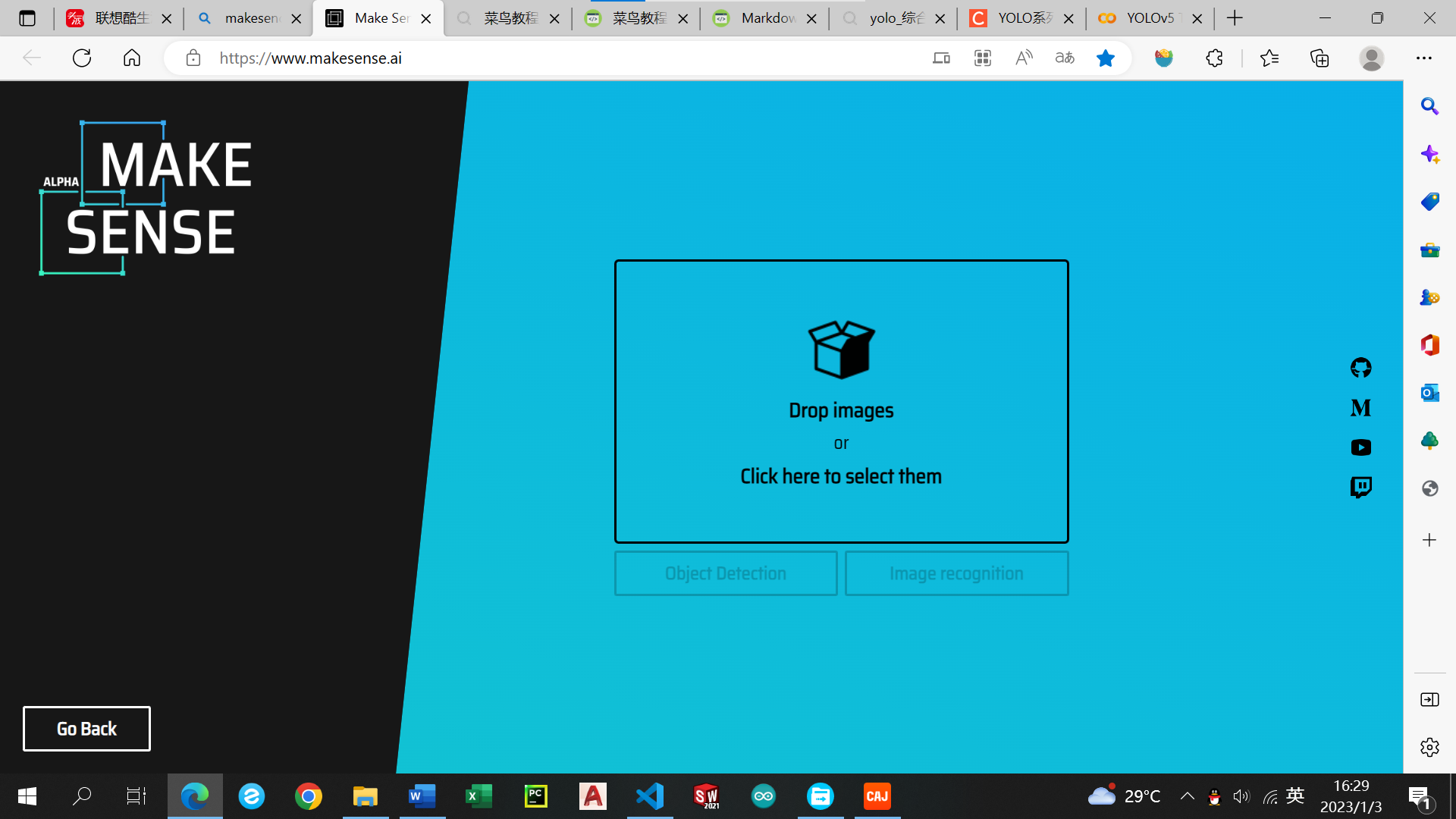
点击Drop images,上传图片,然后点击object detection
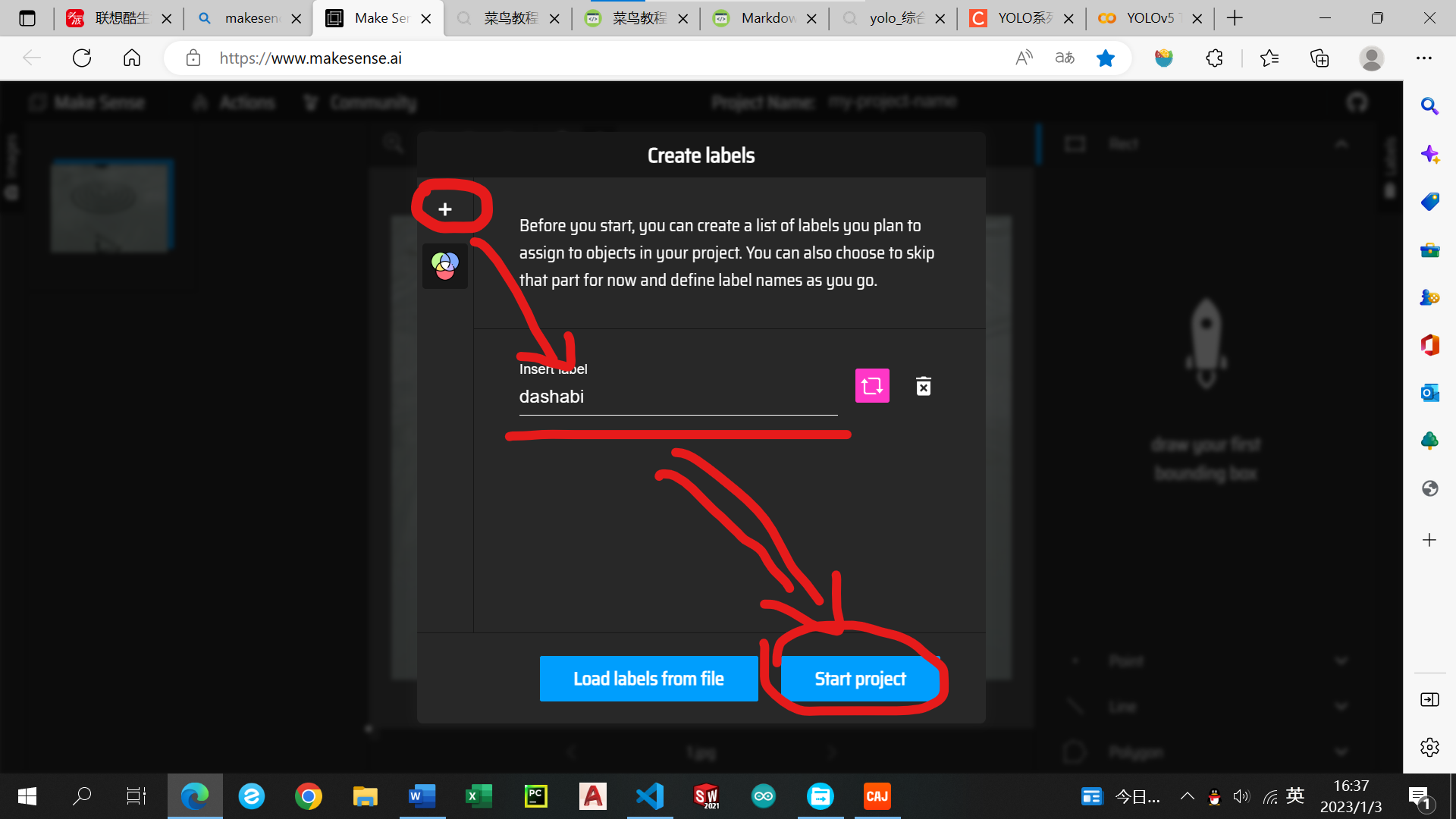
点击+添加标签,输入标签名后点击start porject
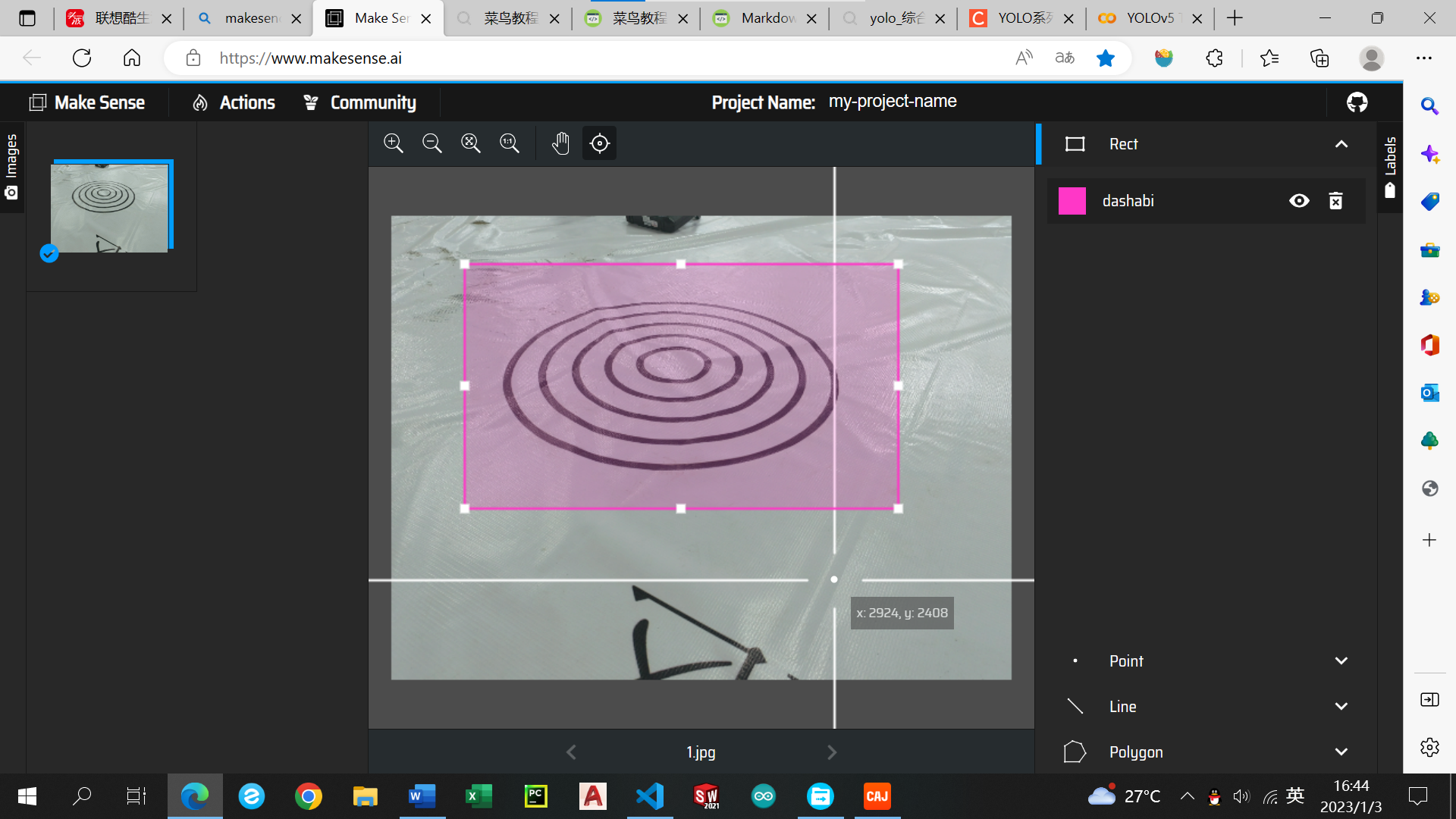
选出识别区域
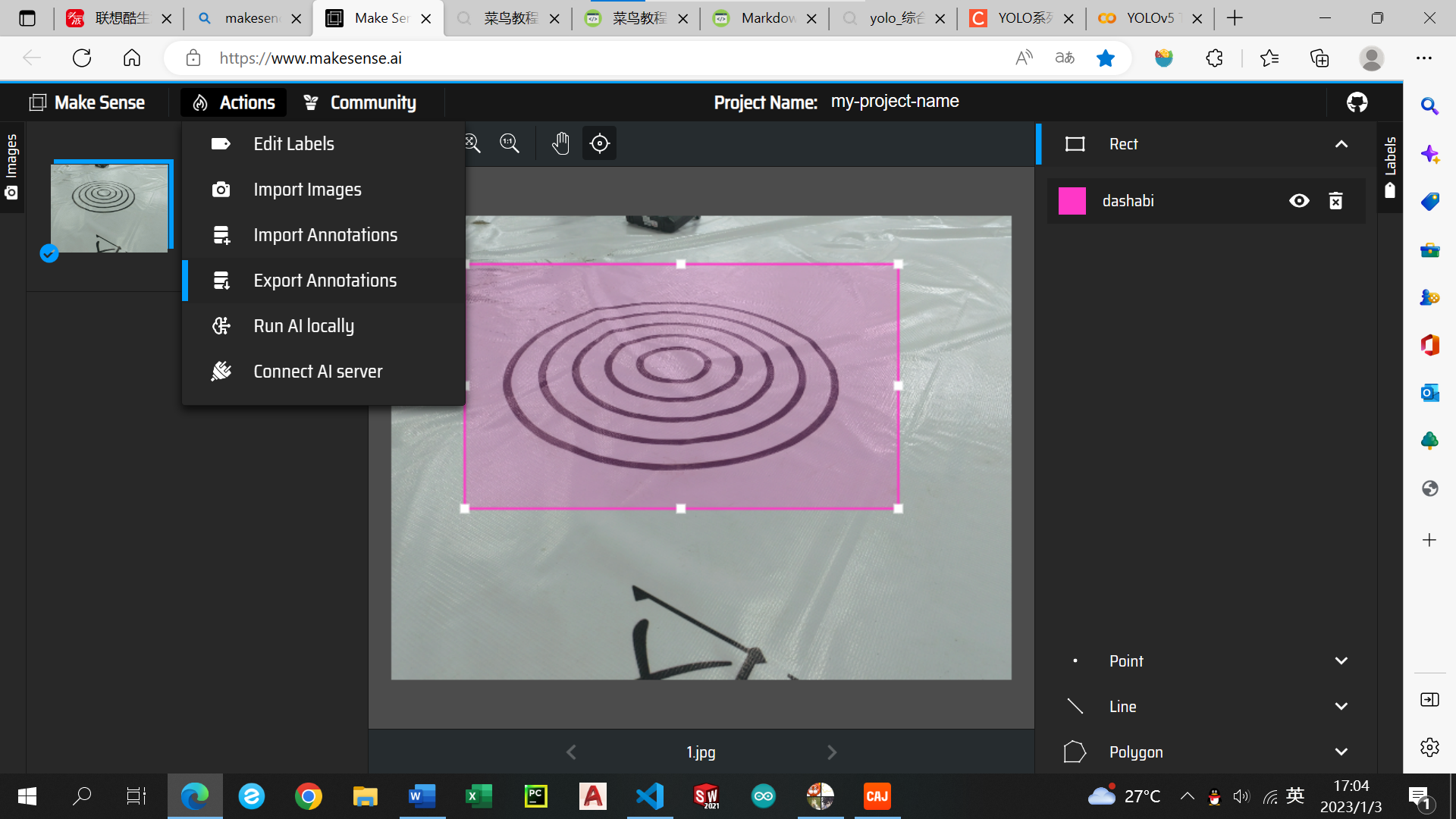
点击Actions--Export Annotatons
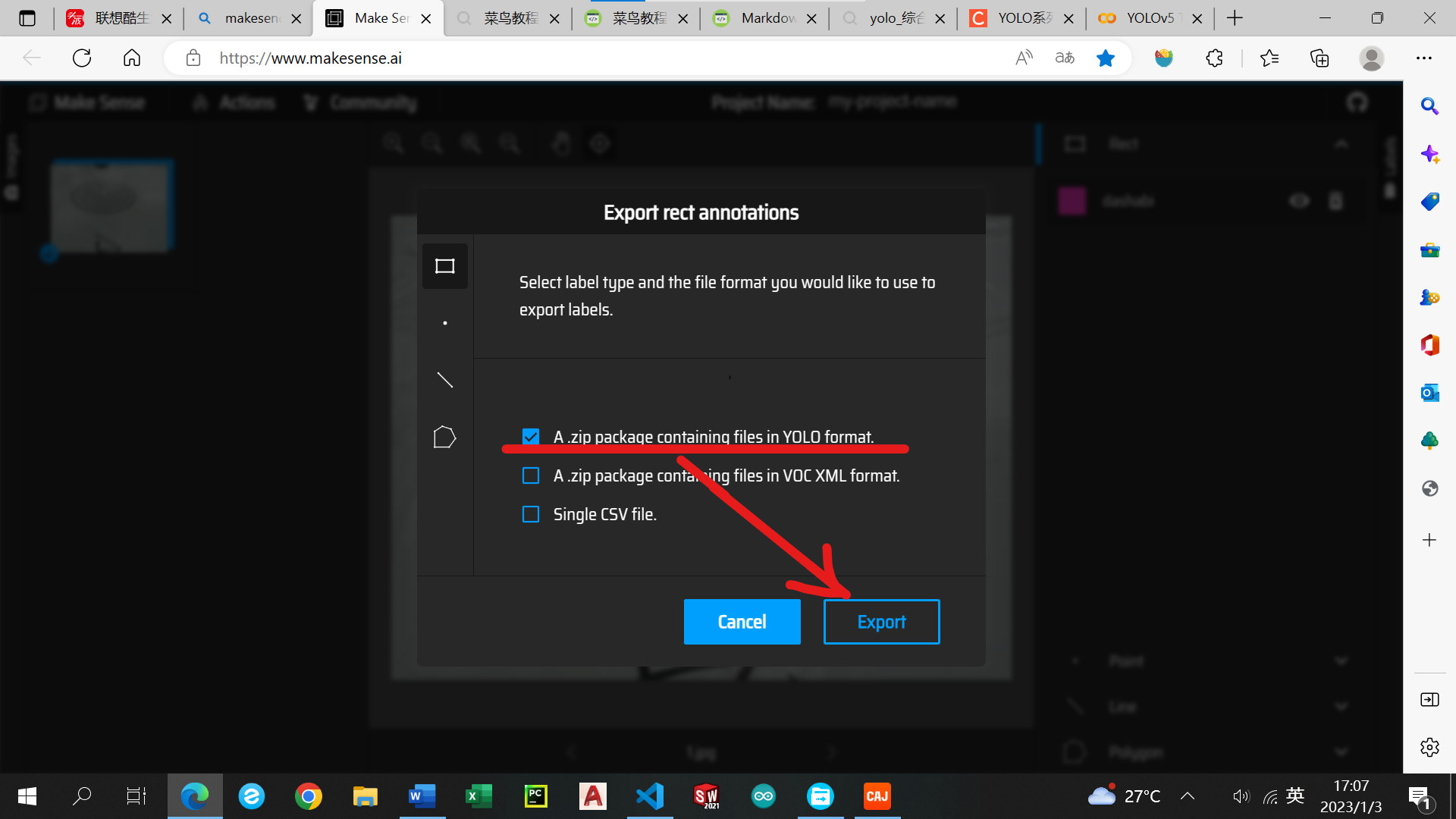
根据图片走
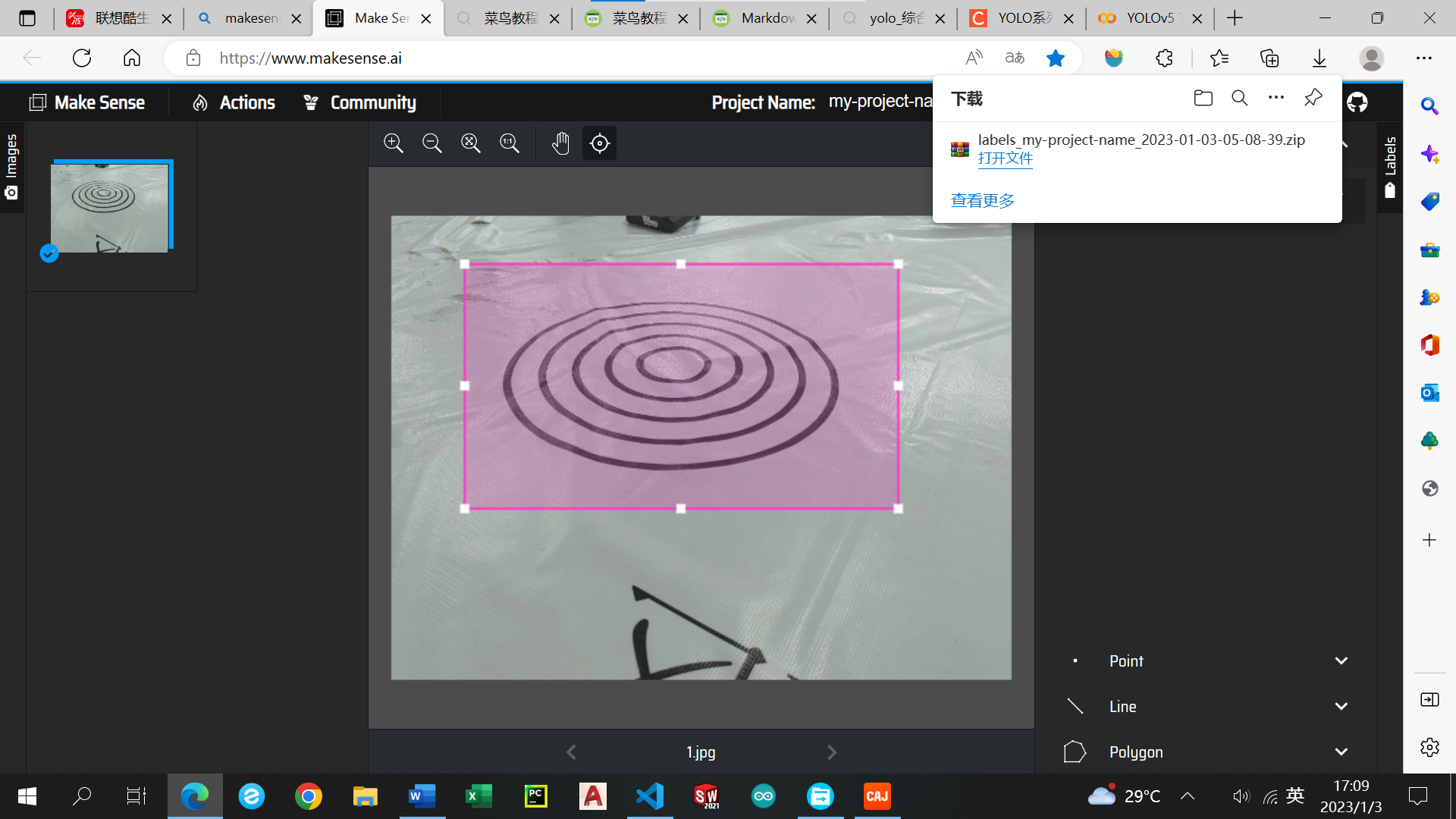
将文件解压后放入labels中,标签要与图片所在的文件夹对应
我们还需要一个yaml文件,根据实际情况修改!,建议用VSCode打开。
train: ../traindata/images/train/ # train images (relative to 'path') 128 images
val: ../traindata/images/val/ # val images (relative to 'path') 128 images
test: # test images (optional)
# Classes
nc: 1 # number of classes
names: ['car'] # class names
# Downloacsyd script/URL (optional)
download: https://ultralytics.com/assets/coco128.zip
train\val后面的地址须与你自己创建的文件夹对应
nc为识别种类数
names为所有种类的名称,注意names的顺序要与makesence里的顺序一致!
将文件夹压缩。
第三步
在GitHub搜索yolov5,如图
进入仓库页面
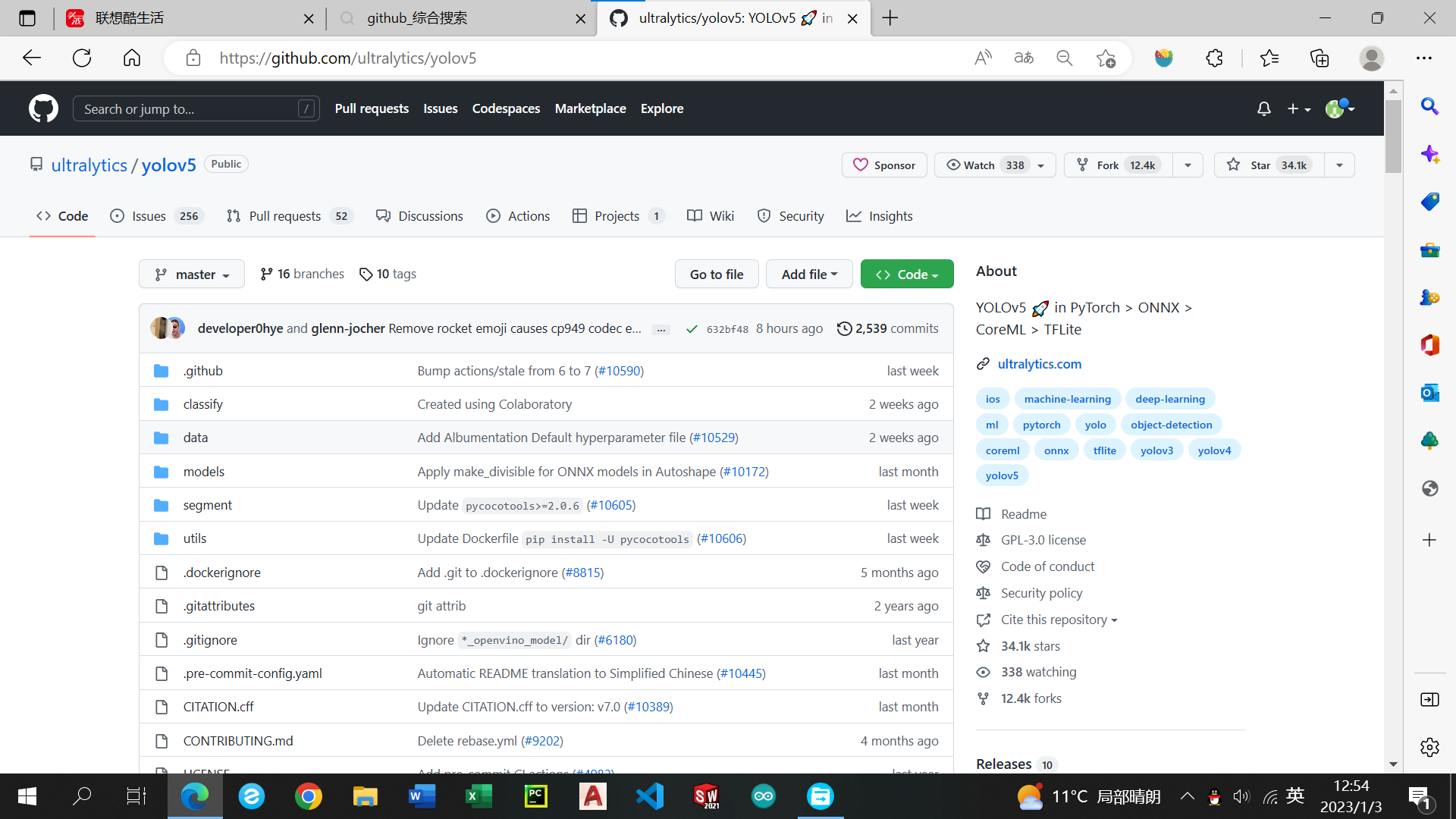
点击open in colab
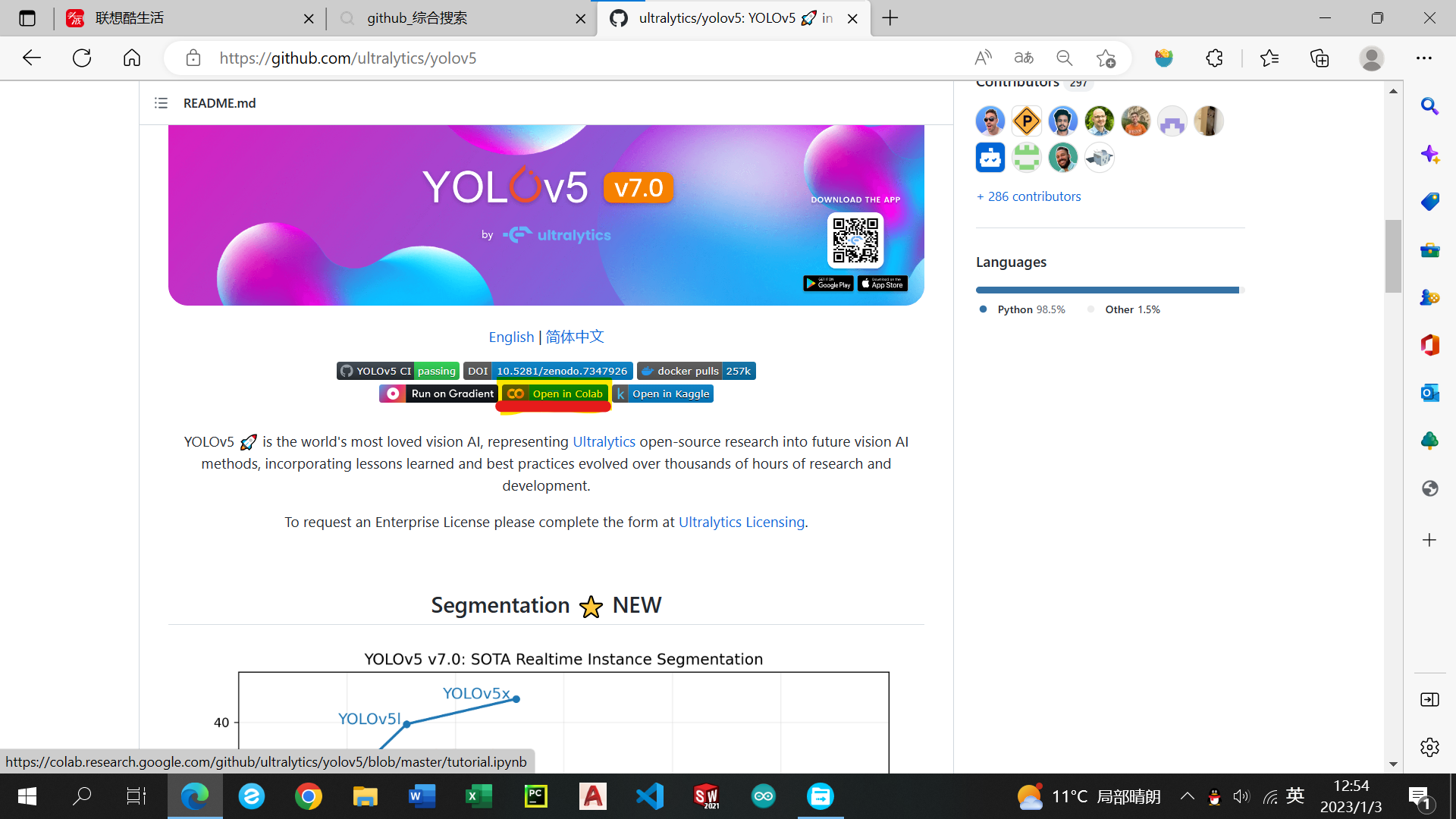
进入后colab主界面
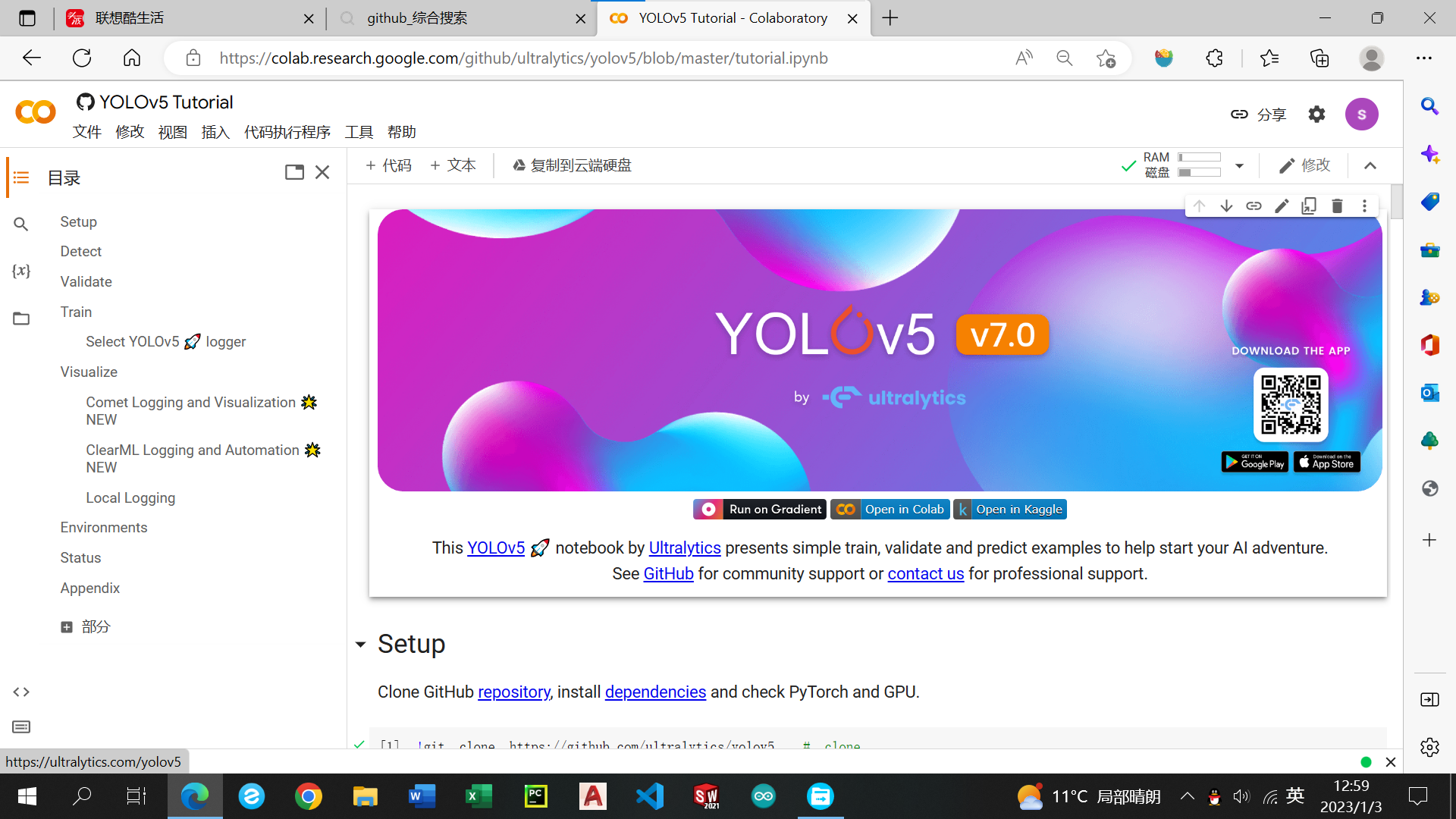
点击运行,成功运行后会跳出yolo5文件夹
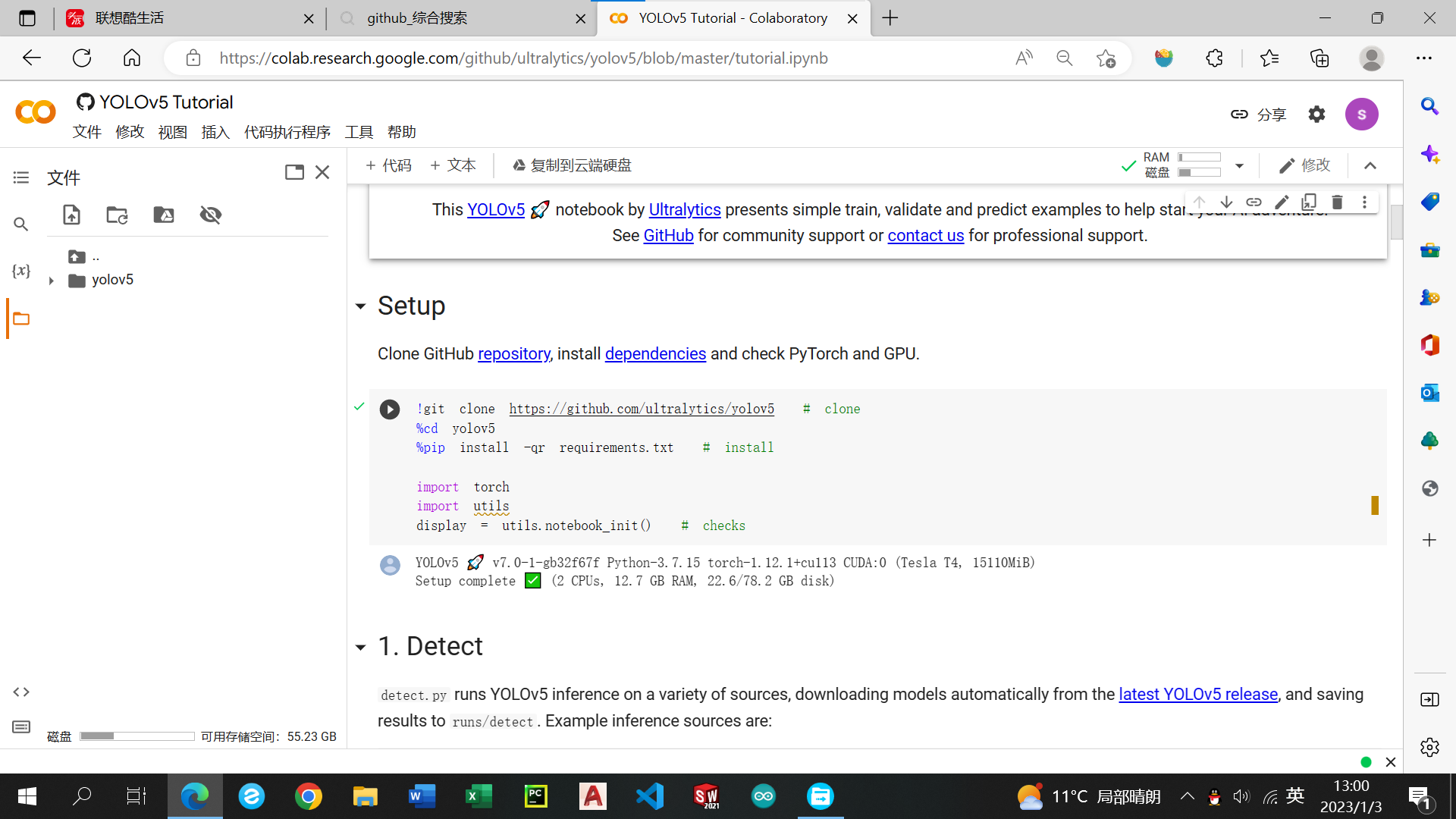
将压缩文件拖进左侧区域,等待黄色小圈加载完
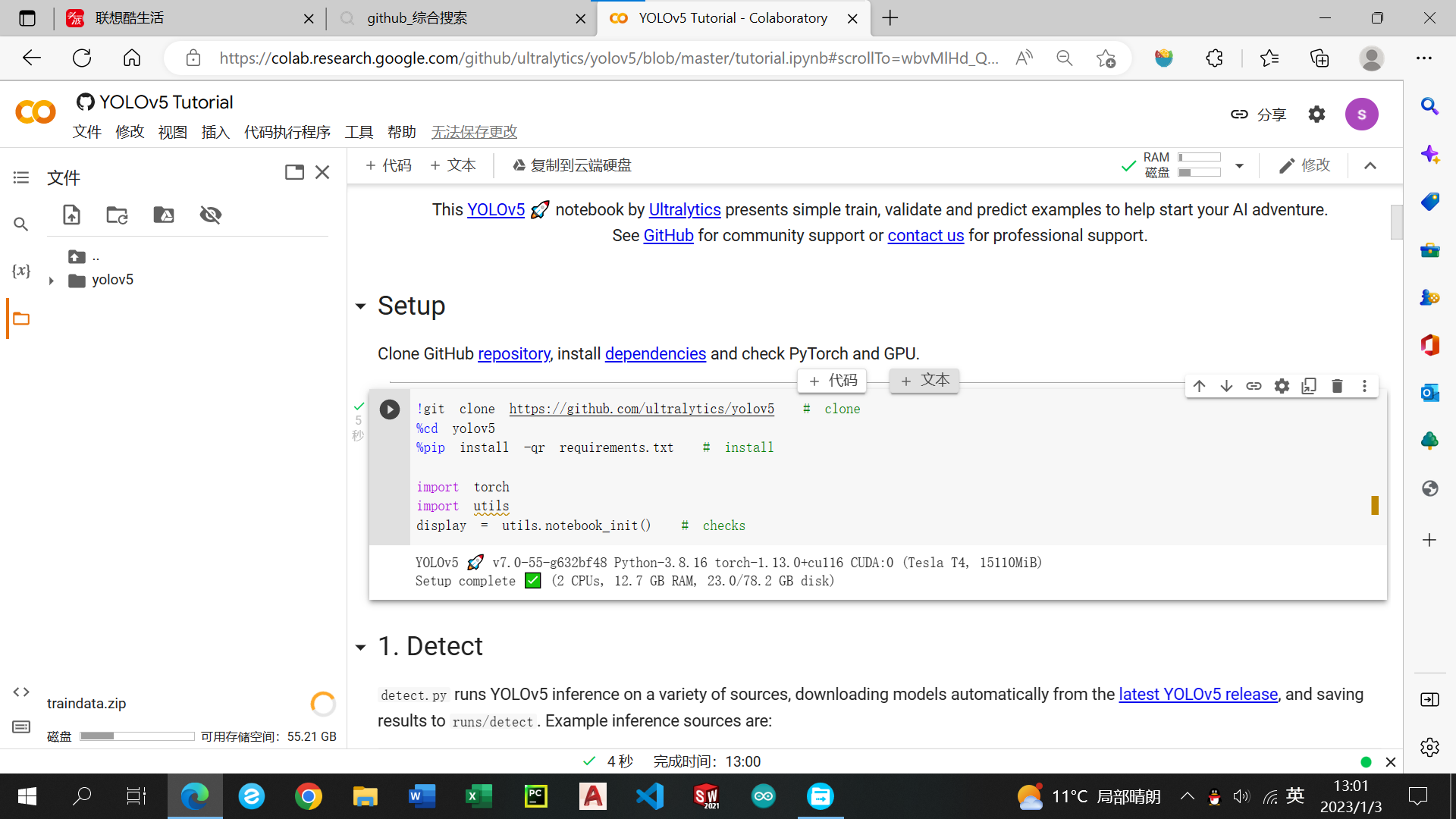
点击+代码,在出现的新单元格中输入!unzip -q ../traindata.zip -d ../
(traindata.zip是文件夹名字根据你命名情况来),点击运行。
注意:可能会出现cannot find traindata.zip之类的问题报错,没有什么很好的解决办法只能刷新左侧文件页面或者主页面。
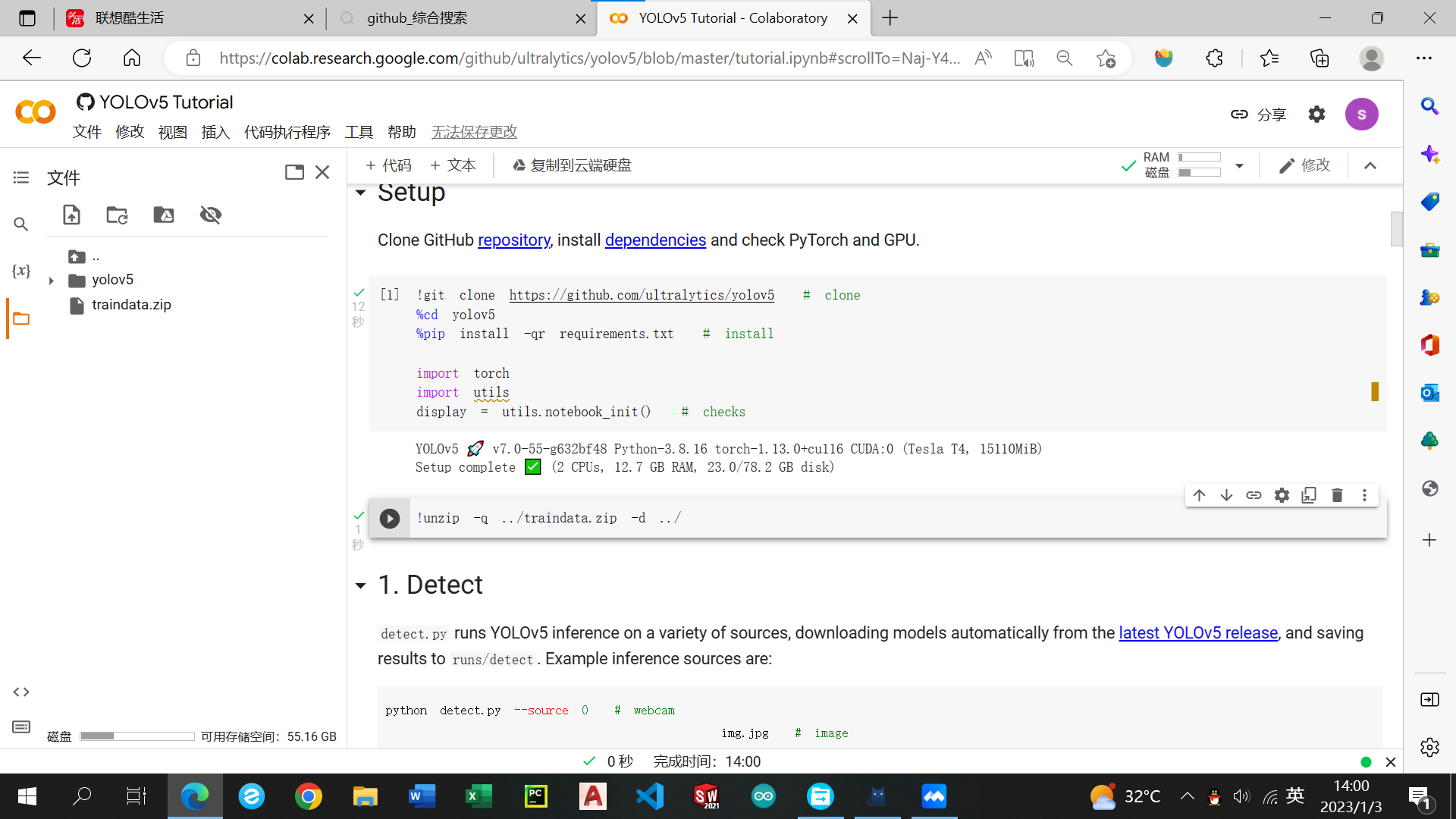
成功运行后会跳出traindata的文件夹,代表运行解压成功
点击yolo5文件夹,找到data文件夹并上传number.yaml文件。找到train.py将-data后的coco128.yaml改为number.yaml。
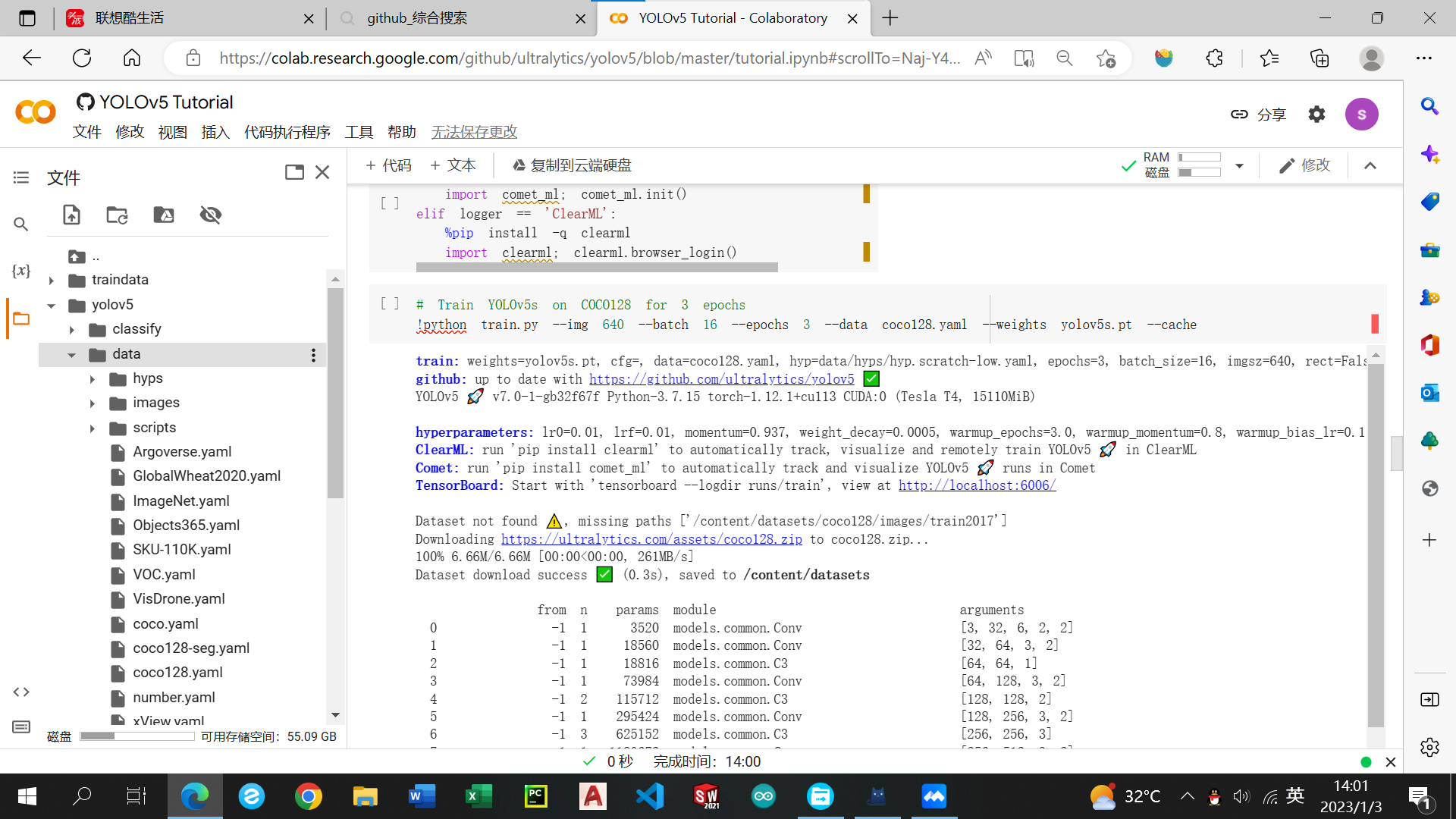
batchs: 每轮投喂的图片数
epochs: 总训练数
weights: 基于训练的模型:yolo5s、yolov5m、yolo5l、yolov5x,训练模型越大速度越慢效果越好。
点击运行,等待模型训练完成。
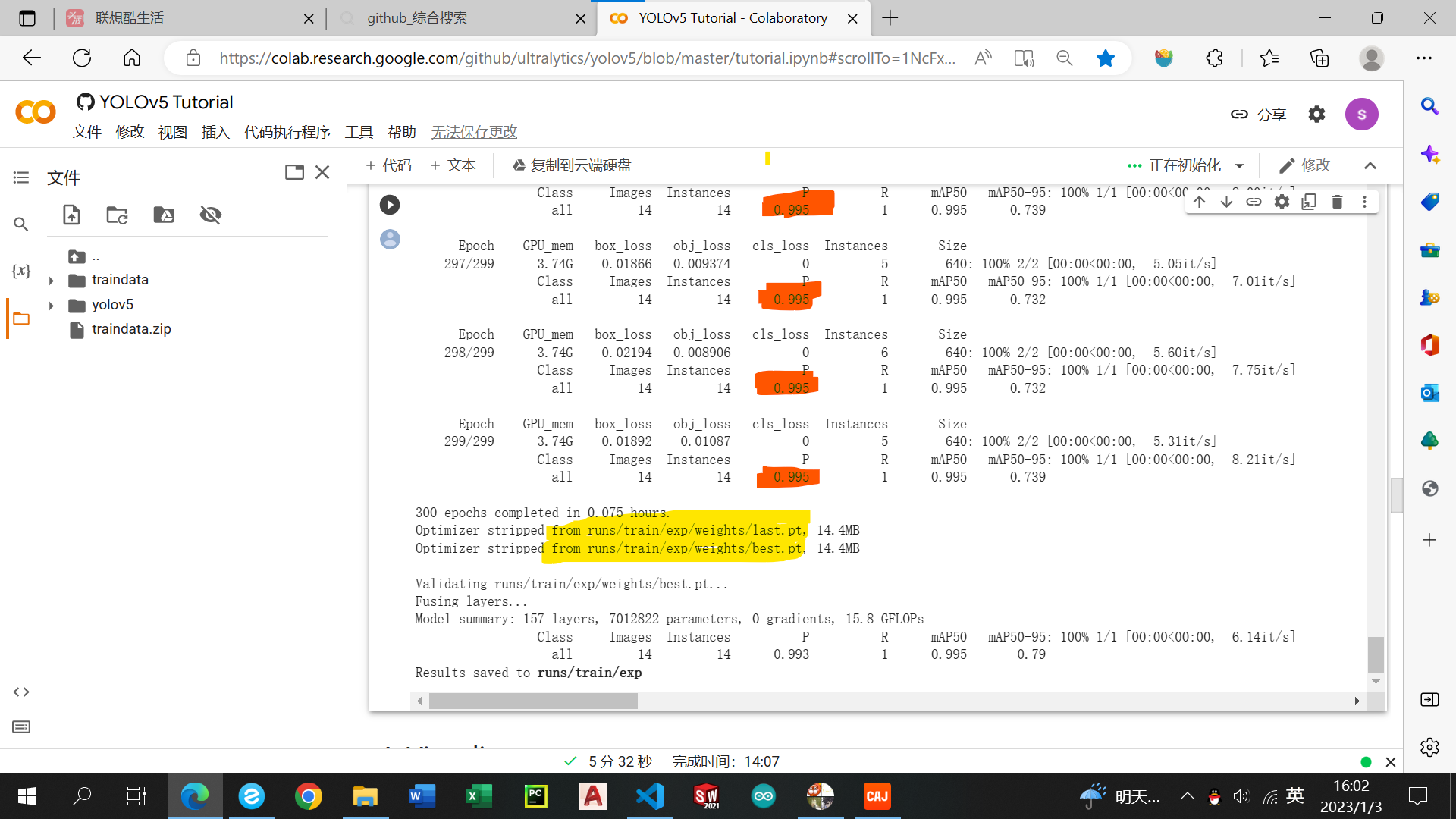
橘红色区域为训练成功率,理论上是逐渐趋于1的。黄色区域是两个权重文件,选择一个复制即可。
第四步
找到detect.py,将--weights后yolov5s.pt改为自己训练的文件地址。
ex:runs/train/exp/weights/best.pt
将欲识别的图片或视频上传至data\images文件夹下,--source后改称图片/视频的名字即可,点击运行。